
大模型使用自身创作的内容作为训练语料,可能会形成一个回音壁效应。这种循环可能会导致大模型在训练过程中不断重复相似的模式和观点,因为模型是在自己的输出上进行训练的。这种情况可能会限制模型的创新能力,并可能导致过拟合现象,即模型过于适应自己的输出,从而降低了对新数据的泛化能力。在使用大模型时需要注意避免过度依赖自我生成的语料,以确保模型的多样性和泛化能力。
随着人工智能技术的飞速发展,大模型的应用越来越广泛,其在图像识别、自然语言处理等领域取得了显著成果,当这些大模型创作的内容又被重新用作训练语料,进一步提升模型的性能时,我们不禁要问:大模型是否会成为一个回音壁?本文将就此问题展开讨论。
大模型的现状与应用
大模型是指参数数量庞大的深度学习模型,如GPT系列、BERT等,这些模型在自然语言处理领域表现出色,能够生成高质量的内容,如文章、诗歌等,大模型在图像识别、语音识别等领域也展现出强大的能力,其应用已经深入到各个领域,如智能客服、自动驾驶等。
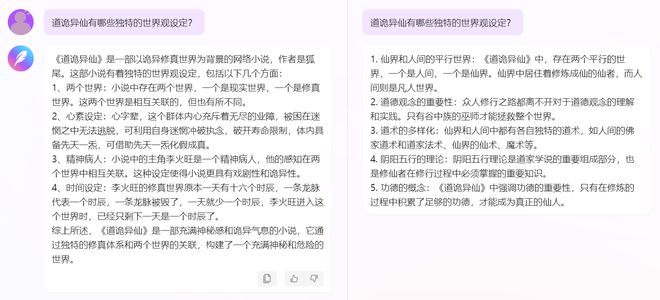
大模型创作的内容具有高质量、多样性等特点,这使得它们成为训练语料的理想选择,这些内容的丰富性和多样性有助于提高模型的泛化能力,使模型在应对不同场景时更加灵活,使用大模型创作的内容作为训练语料,可以加快模型的训练速度,提高模型的性能。
大模型是否会成为一个回音壁?
当大模型创作的内容被重新用作训练语料时,确实存在大模型成为回音壁的风险,模型在训练过程中可能会过度依赖已有的内容,导致生成的内容趋同,缺乏创新,如果训练语料中存在偏见或错误,这些偏见和错误可能会在模型的训练过程中被放大,我们需要关注以下问题:
1、创新与多样性的平衡:虽然使用大模型创作的内容作为训练语料可以提高模型的性能,但我们需要寻找平衡,保持模型的创新能力,避免生成的内容趋同。
2、偏见与错误的防范:对训练语料进行严格的筛选和预处理,以确保其质量和准确性,防止偏见和错误的放大。

3、模型自我改进的限制:为了避免模型陷入局部最优解,我们需要不断探索新的训练方法和技术,以促进模型的持续进步。
解决方案与未来展望
为了避免大模型成为回音壁,我们需要采取以下措施:
1、引入多样化训练语料:除了使用大模型创作的内容作为训练语料外,还需要引入其他来源的语料,如互联网数据、专业数据集等,以提高模型的泛化能力。
2、加强数据筛选与预处理:对训练语料进行严格的筛选和预处理,去除其中的偏见和错误,采用数据增强技术,提高模型的鲁棒性。
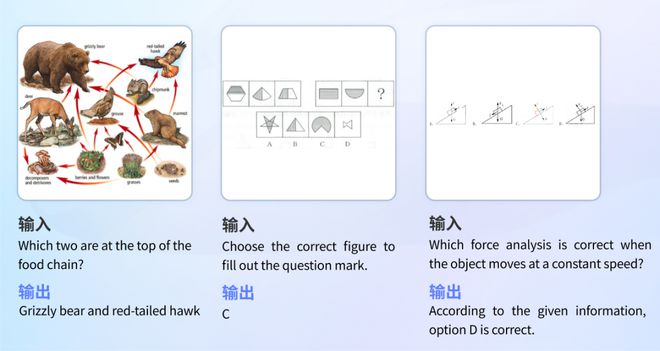
3、探索新的训练方法和技术:不断研究新的训练方法和技术,如迁移学习、多任务学习等,以帮助模型在自我学习的过程中保持创新和进步。
展望未来,随着人工智能技术的不断发展,大模型的应用将更加广泛,我们需要不断解决大模型面临的问题和挑战,如避免成为回音壁等,通过引入多样化训练语料、加强数据筛选与预处理以及探索新的训练方法和技术等措施,我们可以进一步提高大模型的性能和应用价值,只有这样,我们才能充分发挥大模型的潜力,为人工智能的发展做出更大的贡献。
 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号